
Diffusion Transformers have demonstrated superior performance in video synthesis, however previous motion transfer methods are engineered for UNets or do not take into account the full spatio-temporal information available with DiT's 3D attention mechanism.
We propose DiTFlow, a method for transferring the motion of a reference video to a newly synthesized one, designed specifically for DiTs.
We first process the reference video with a pre-trained DiT to analyze cross-frame attention maps and extract a patch-wise motion signal called the Attention Motion Flow (AMF). We guide the latent denoising process in an optimization-based, training-free, manner by optimizing latents with our AMF loss to generate videos reproducing the motion of the reference one. We also apply our optimization strategy to transformer positional embeddings, granting us a boost in zero-shot motion transfer capabilities. We evaluate DiTFlow against recently published methods, outperforming all across multiple metrics and human evaluation.
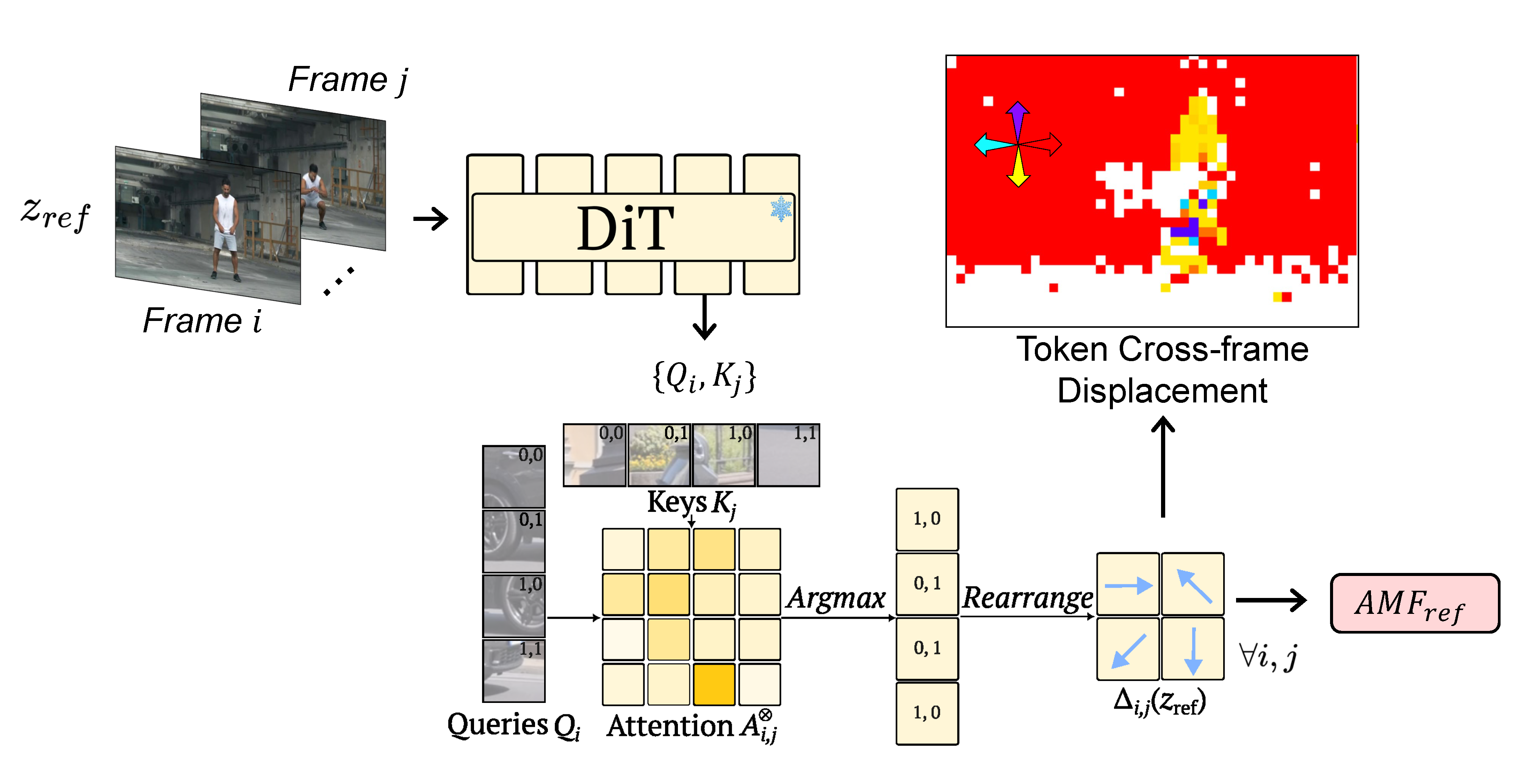
We observe that the cross-frame attention maps of DiTs contain rich motion signals through correspondences between frames. The queries and keys at a given DiT block between a pair of frames can be used to get cross-frame attention. We obtain a displacement vector for each query location by finding the key location with the highest attention score (see paper for details).
The extracted displacement vectors between each frame pair is visualised below with a color map (e.g. red is rightwards motion of the camera and yellow is downwards motion of the player from frame 0 to frame 4). Feel free to select the first frame using the dropdown menu and use the slider to select the second frame to see the motion flow between the two.

We transfer motion during the latent diffusion process by optimizing the noisy latents with a loss between the AMF of the reference and generated frames. These optimization steps occur in the early denoising steps, while later steps are unguided.
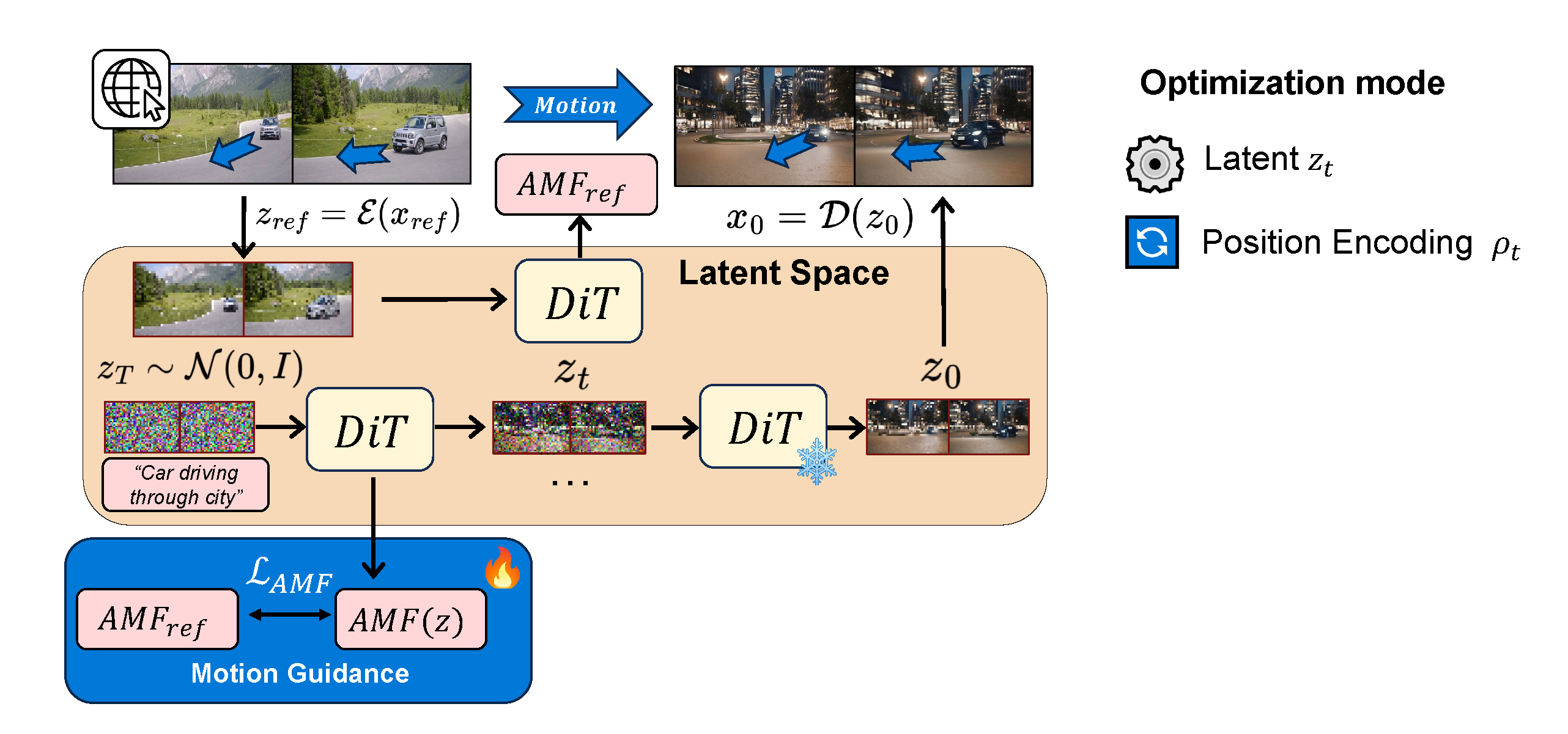
An alternative approach is to optimize transformer positional embeddings to transfer motion - intuitively guiding the reorganization of latent patches. Afterwards, we can inject our optimized positional embeddings to a new prompt to generate guided videos without any additional training.

Check out Supplementary for more results.
Please check out the excellent existing work that tackles the motion transfer problem.
SMM and MOFT do optimization-based, training-free motion transfer for UNet-based diffusion models using spatially-averaged and motion channel filtered features respectively. MotionClone applies guidance directly to UNet temporal attention values to guide motion.
Many recent works also try to disentangle motion by training a model conditioned on motion trajectories.
@inproceedings{pondaven2025ditflow,
title={Video Motion Transfer with Diffusion Transformers},
author={Alexander Pondaven and Aliaksandr Siarohin and Sergey Tulyakov and Philip Torr and Fabio Pizzati},
booktitle={CVPR},
year={2025}
}